Эволюция обработки естественного языка: фрагментированная ИИ-система к основным моделям
Определения
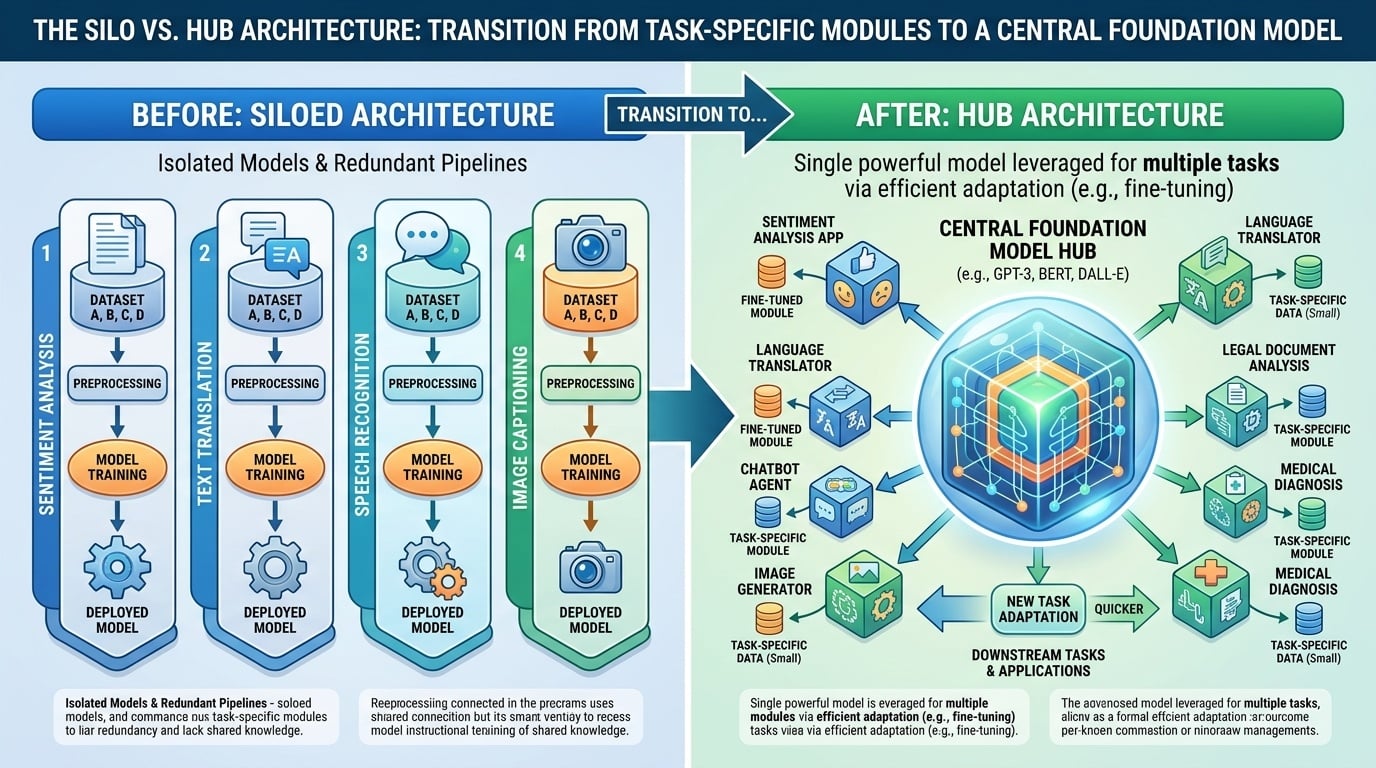
- Фрагментированная ИИ-система: Эпоха, определяемая разрозненными, специализированными нейронными архитектурами, созданными для конкретных задач, таких как маркировка последовательностей или классификация.
- Основная модель: Унифицированная, монолитная архитектура трансформаторов, которая рассматривает все языковые проблемы как генеративную текст-в-текст последовательность $x \rightarrow y$.
Ключевые концепции
- Архитектурная интеграция: Раньше обработка естественного языка требовала специализированные пайплайны (Би-ЛСТМ для распознавания именованных сущностей, сверточные нейронные сети для анализа тональности). Модели большого языка объединяют эти изоляционные структуры в один центральный блок, где одни и те же веса используются для всех задач.
- Единый интерфейс: Модели большого языка заменяют специализированные "выходные головки" (например, 3-классовый софтмакс) на естественно-языковой интерфейс. Входы и выходы всегда являются строками, позволяя модели интерпретировать намерение а не формат.
- Передача знаний: Традиционные модели были "чистыми листами" для каждой задачи. Модели большого языка приоризируют Обобщение первым, где конкретные задачи являются простым применением предварительно существующего, надежного внутреннего представления языка.
Исторический контекст
- До 2018 года: Изоляция задач требовала обучения различных моделей с разными функциями потерь $\mathcal{L}_{task}$.
- Современная эпоха: Парадигма "текст-в-текст" позволяет одной модели (например, Llama-3) переключаться между задачами с помощью нулевого или малого числа примеров.
Сравнение реализации на Python